
For det første er den eneste sikkerhed, at der ikke er nogen sikkerhed. For det andet er enhver beslutning som konsekvens et spørgsmål om at afveje sandsynligheder. For det tredje skal vi på trods af usikkerhed beslutte os, og vi skal handle. Og endelig skal vi bedømme beslutninger ikke kun ud fra resultaterne, men hvordan disse beslutninger blev truffet. – Robert E. Rubin
Et af de vigtigste og mest udfordrende aspekter af prognoser er at håndtere den usikkerhed, der er forbundet med at undersøge fremtiden. Efter at have bygget og udfyldt hundredvis af finansielle og driftsmodeller for LBO'er, startup fundraisings, budgetter, M&A og virksomhedens strategiske planer siden 2003, har jeg været vidne til en bred vifte af tilgange til at gøre det. Hvert administrerende direktør, finansdirektør, bestyrelsesmedlem, investor eller investeringsudvalgsmedlem medbringer deres egen erfaring og tilgang til finansielle fremskrivninger og usikkerhed – påvirket af forskellige incitamenter. Ofte giver sammenligning af faktiske resultater med fremskrivninger en forståelse for, hvor store afvigelserne mellem prognoser og faktiske resultater kan være, og derfor behovet for at forstå og eksplicit erkende usikkerhed.
Jeg startede med at bruge scenarie- og følsomhedsanalyser til at modellere usikkerhed, og betragter dem stadig som meget nyttige værktøjer. Siden jeg tilføjede Monte Carlo-simuleringer til min værktøjskasse i 2010, har jeg oplevet, at de er et ekstremt effektivt værktøj til at forfine og forbedre, hvordan du tænker om risiko og sandsynligheder. Jeg har brugt tilgangen til alt fra at konstruere DCF-vurderinger, værdiansætte købsoptioner i M&A og diskutere risici med långivere til at søge finansiering og vejlede tildelingen af VC-finansiering til startups. Tilgangen er altid blevet godt modtaget af bestyrelsesmedlemmer, investorer og topledelsesteams. I denne artikel giver jeg en trin-for-trin vejledning om brug af Monte Carlo-simuleringer i praksis ved at bygge en DCF-værdiansættelsesmodel.
Inden vi starter med casestudiet, lad os gennemgå et par forskellige tilgange til håndtering af usikkerhed. Begrebet forventet værdi —det sandsynlighedsvægtede gennemsnit af pengestrømme i alle mulige scenarier — er Finance 101. Men finansprofessionelle og beslutningstagere mere bredt tager meget forskellige tilgange, når de omsætter denne simple indsigt til praksis. Tilgangen kan spænde fra simpelthen ikke at genkende eller diskutere usikkerhed på den ene side til sofistikerede modeller og software på den anden side. I nogle tilfælde ender folk med at bruge mere tid på at diskutere sandsynligheder end på at beregne pengestrømme.
Udover blot ikke at tage fat på det, lad os undersøge nogle få måder at håndtere usikkerhed på i mellem- eller langsigtede fremskrivninger. Mange af disse burde være bekendt for dig.
| Oprettelse af ét scenarie. Denne tilgang er standard for budgetter, mange startups og endda investeringsbeslutninger. Udover at den ikke indeholder nogen information om graden af usikkerhed eller erkendelse af, at resultater kan afvige fra fremskrivningerne, kan den være tvetydig og fortolkes forskelligt alt efter interessenten. Nogle vil måske tolke det som et strækmål, hvor det faktiske resultat er mere tilbøjeligt til at komme til kort end overskride. Nogle ser det som en baseline-præstation med flere opadrettede end ulemper. Andre kan se det som en "Base Case" med 50/50 sandsynlighed op og ned. I nogle tilgange, især for startups, er det meget ambitiøst, og fiasko eller underskud er langt det mere sandsynlige resultat, men en højere diskonteringsrente bruges i et forsøg på at tage højde for risikoen. | 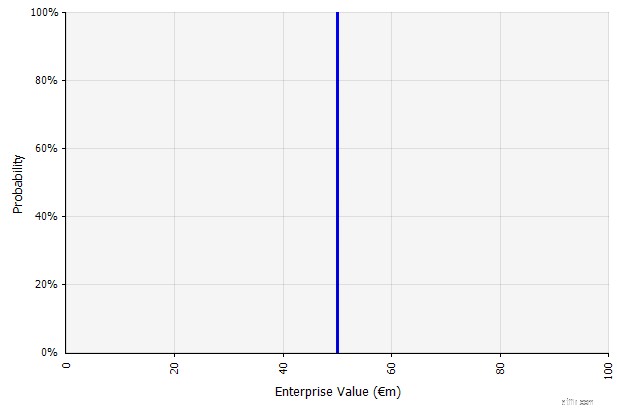 Inputtene i den langsigtede likviditetsprognose under denne tilgang er alle punktestimater, hvilket giver et punktestimatresultat på €50 millioner i dette eksempel med en implicit sandsynlighed på 100 %. |
| Oprettelse af flere scenarier. Denne tilgang erkender, at det er usandsynligt, at virkeligheden udfolder sig i henhold til en enkelt given plan.
| 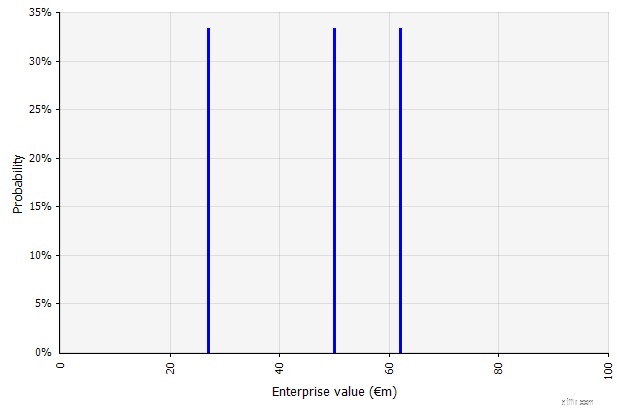 De tre forskellige scenarier giver tre forskellige resultater, som her antages at være lige sandsynlige. Sandsynligheden for udfald uden for de høje og lave scenarier tages ikke i betragtning. |
| Oprettelse af base-, upside- og downside-tilfælde med sandsynligheder, der udtrykkeligt er anerkendt. Det vil sige, at bjørne- og tyrsagen indeholder for eksempel 25 % sandsynlighed i hver hale, og dagsværdiestimatet repræsenterer midtpunktet. En nyttig fordel ved dette fra et risikostyringsperspektiv er den eksplicitte analyse af halerisiko, dvs. begivenheder uden for op- og nedadgående scenarier. | Illustration fra Morningstar Valuation Handbook 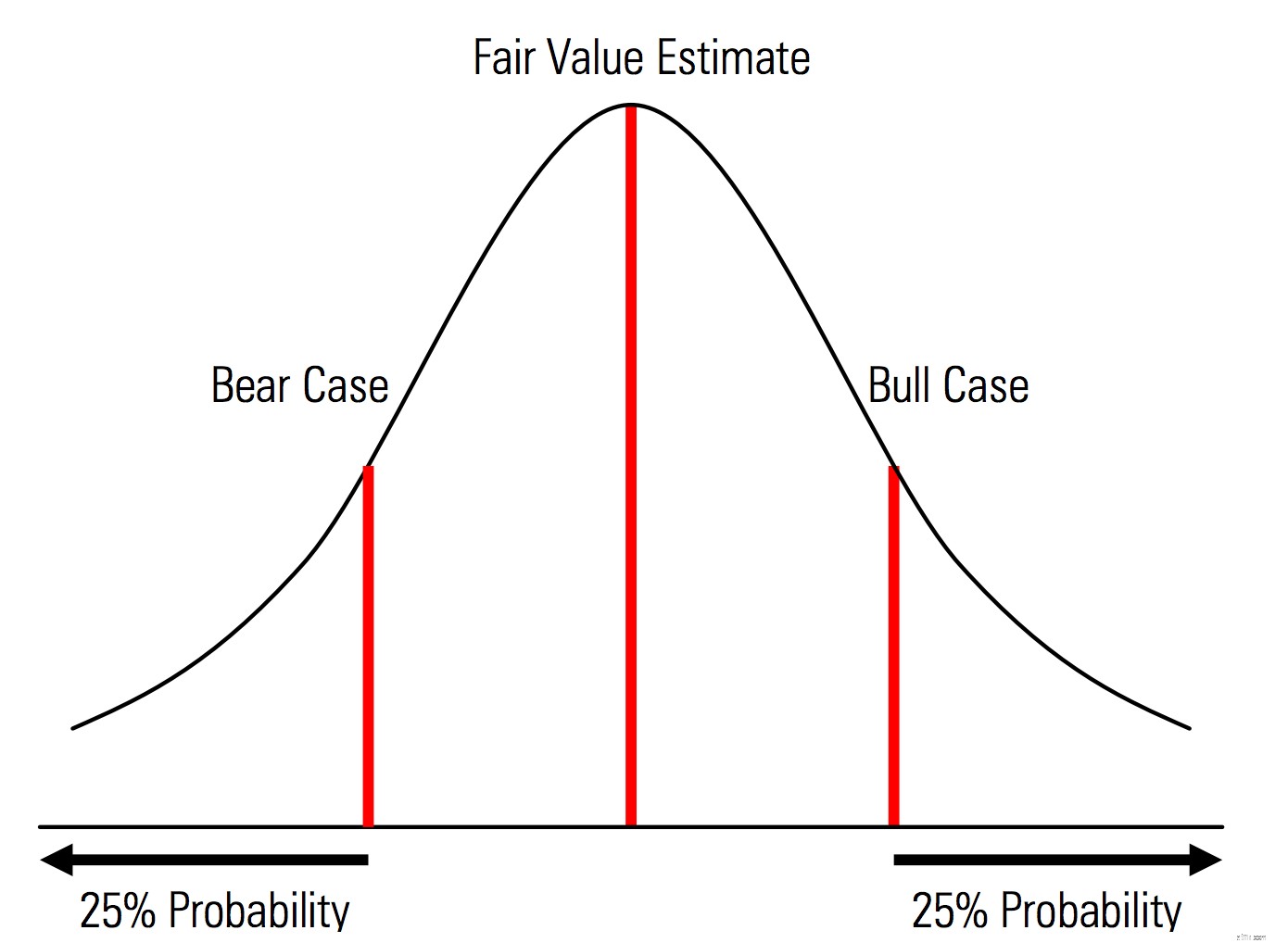 |
| Brug af sandsynlighedsfordelinger og Monte Carlo-simuleringer. Brug af sandsynlighedsfordelinger giver dig mulighed for at modellere og visualisere hele spektret af mulige udfald i prognosen. Dette kan gøres ikke kun på et aggregeret niveau, men også for detaljerede individuelle input, antagelser og drivere. Monte Carlo metoder bruges derefter til at beregne de resulterende sandsynlighedsfordelinger på et aggregeret niveau, hvilket giver mulighed for analyse af, hvordan flere usikre variable bidrager til usikkerheden i de samlede resultater. Måske vigtigst af alt tvinger tilgangen alle involverede i analysen og beslutningen til eksplicit at erkende den usikkerhed, der er forbundet med prognoser, og til at tænke i sandsynligheder. Ligesom de andre tilgange har dette sine ulemper, herunder risikoen for falsk præcision og deraf følgende oversikkerhed, der kan følge med at bruge en mere sofistikeret model, og det ekstra arbejde, der kræves for at vælge passende sandsynlighedsfordelinger og estimere deres parametre, hvor ellers kun punktestimater ville være brugt. | 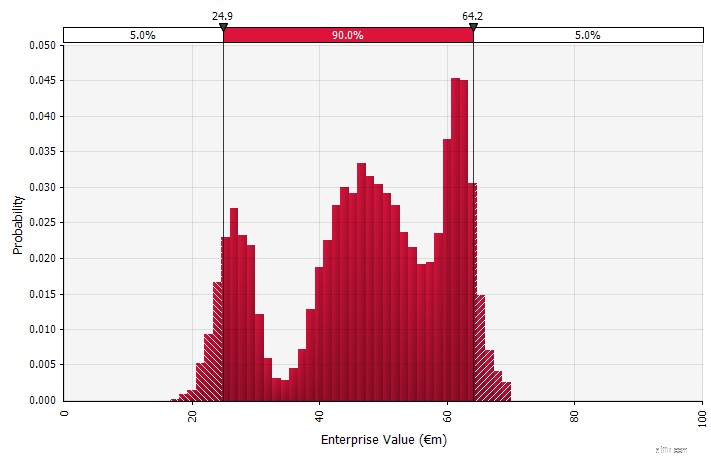 |
Monte Carlo-simuleringer modellerer sandsynligheden for forskellige udfald i finansielle prognoser og estimater. De tjener deres navn fra området Monte Carlo i Monaco, som er verdensberømt for sine eksklusive kasinoer; tilfældige udfald er centrale for teknikken, ligesom de er for roulette og spilleautomater. Monte Carlo-simuleringer er nyttige inden for en bred vifte af områder, herunder teknik, projektledelse, olie- og gasefterforskning og andre kapitalintensive industrier, F&U og forsikring; her fokuserer jeg på applikationer inden for økonomi og forretning.
I simuleringen er de usikre input beskrevet ved hjælp af sandsynlighedsfordelinger, beskrevet af parametre som middelværdi og standardafvigelse. Eksempler på input i finansielle fremskrivninger kan være alt fra indtægter og marginer til noget mere detaljeret, såsom råvarepriser, kapitaludgifter til en udvidelse eller udenlandske valutakurser.
Når en eller flere inputs beskrives som sandsynlighedsfordelinger, bliver outputtet også en sandsynlighedsfordeling. En computer trækker tilfældigt et tal fra hver inputfordeling og beregner og gemmer resultatet. Dette gentages hundreder, tusinder eller titusinder af gange, hver kaldet en iteration. Når de tages sammen, tilnærmer disse iterationer sandsynlighedsfordelingen af det endelige resultat.
Inputfordelingerne kan enten være kontinuerlige , hvor den tilfældigt genererede værdi kan tage en hvilken som helst værdi under fordelingen (for eksempel en normalfordeling), eller diskret , hvor sandsynligheder er knyttet til to eller flere adskilte scenarier.
En simulering kan også indeholde en blanding af fordelinger af forskellige typer. Tag for eksempel et farmaceutisk R&D-projekt med flere faser, der hver især har en diskret sandsynlighed for succes eller fiasko. Dette kan kombineres med løbende distributioner, der beskriver usikre investeringsbeløb, der er nødvendige for hver fase og potentielle indtægter, hvis projektet resulterer i et produkt, der når markedet. Diagrammet nedenfor viser output fra en sådan simulering:en ~65 % sandsynlighed for at miste hele investeringen på 5 mio. EUR til 50 mio. EUR (nutidsværdi) og en ~35 % sandsynlighed for en nettogevinst, der højst sandsynligt ligger i intervallet €100 til €250 – information, der ville gå tabt, hvis nøgleoutputmålinger såsom MIRR eller NPV vises som punktestimater frem for sandsynlighedsfordelinger.
Eksempel Monte Carlo-simulering for et projekt med flere Go/No-go-stadier og usikre investeringer imellem, med usikker værdi, hvis projektet når færdiggørelse
En af grundene til, at Monte Carlo-simuleringer ikke er mere udbredt, er, at typiske finansielle daglige værktøjer ikke understøtter dem særlig godt. Excel og Google Sheets har ét tal eller formelresultat i hver celle, og selvom de kan definere sandsynlighedsfordelinger og generere tilfældige tal, er det besværligt at bygge en finansiel model med Monte Carlo-funktionalitet fra bunden. Og mens mange finansielle institutioner og investeringsselskaber bruger Monte Carlo-simuleringer til at værdiansætte derivater, analysere porteføljer og mere, er deres værktøjer typisk udviklet internt, proprietære eller uoverkommeligt dyre – hvilket gør dem utilgængelige for den enkelte finansprofessionel.
Derfor vil jeg henlede opmærksomheden på Excel-plugins som @RISK by Palisade, ModelRisk by Vose og RiskAMP, som i høj grad forenkler arbejdet med Monte Carlo-simuleringer og giver dig mulighed for at integrere dem i dine eksisterende modeller. I den følgende gennemgang vil jeg bruge @RISK.
Lad os gennemgå et simpelt eksempel, der illustrerer nøglebegreberne i en Monte Carlo-simulering:en femårig pengestrømsprognose. I denne gennemgang opsætter og udfylder jeg en grundlæggende pengestrømsmodel til værdiansættelsesformål, erstatter gradvist input med sandsynlighedsfordelinger og kører til sidst simuleringen og analyserer resultaterne.
Til at starte med bruger jeg en simpel model, der fokuserer på at fremhæve nøglefunktionerne ved at bruge sandsynlighedsfordelinger. Bemærk, at for at starte med er denne model ikke forskellig fra enhver anden Excel-model; de plugins, jeg nævnte ovenfor, fungerer med dine eksisterende modeller og regneark. Modellen nedenfor er en simpel hyldeversion fyldt med antagelser for at danne ét scenario.
Først skal vi indsamle den information, der er nødvendig for at lave vores antagelser, derefter skal vi vælge de korrekte sandsynlighedsfordelinger at indsætte. Det er vigtigt at bemærke, at kilden til de vigtigste input/antagelser er den samme, uanset hvilken tilgang du tager til at håndtere usikkerhed. Kommerciel due diligence, en omfattende gennemgang af virksomhedens forretningsplan i sammenhæng med forventet markedsudvikling, industritrends og konkurrencedynamik, omfatter typisk ekstrapolering fra historiske data, inkorporering af ekspertudtalelser, udførelse af markedsundersøgelser og interview af markedsdeltagere. Efter min erfaring er eksperter og markedsdeltagere glade for at diskutere forskellige scenarier, risici og rækker af resultater. De fleste beskriver dog ikke eksplicit sandsynlighedsfordelinger.
Lad os nu gå igennem og erstatte vores vigtigste inputværdier med sandsynlighedsfordelinger én efter én, begyndende med den estimerede salgsvækst for det første prognoseår (2018). @RISK-pluginnet til Excel kan evalueres med en 15-dages gratis prøveperiode, så du kan downloade det fra Palisade-webstedet og installere det med et par klik. Med @RISK plugin aktiveret, vælg den celle, du vil have distributionen i, og vælg "Definer distribution" i menuen.
Du vælger derefter en fra paletten af distributioner, der kommer op. @RISK-softwaren tilbyder mere end 70 forskellige distributioner at vælge imellem, så at vælge en kan virke overvældende i starten. Nedenfor er en guide til en håndfuld jeg bruger oftest:
| Normal. Defineret ved middelværdi og standardafvigelse. Dette er et godt udgangspunkt på grund af dets enkelthed og velegnet som en udvidelse til Morningstar-tilgangen, hvor du definerer en fordeling, der dækker måske allerede definerede scenarier eller intervaller for et givent input, og sikrer, at sagerne er symmetriske omkring basissagen og at sandsynligheden for hver hale ser rimelig ud (f.eks. 25 % som i Morningstar-eksemplet). | 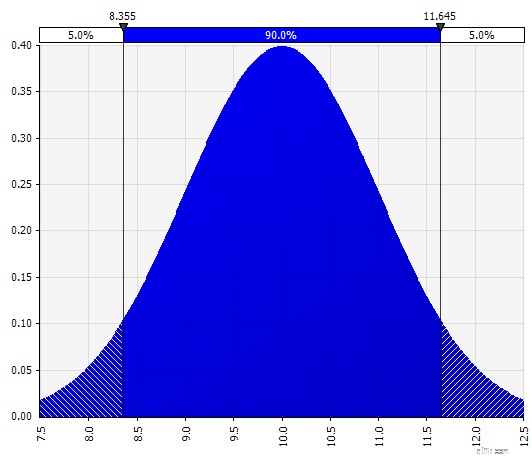 |
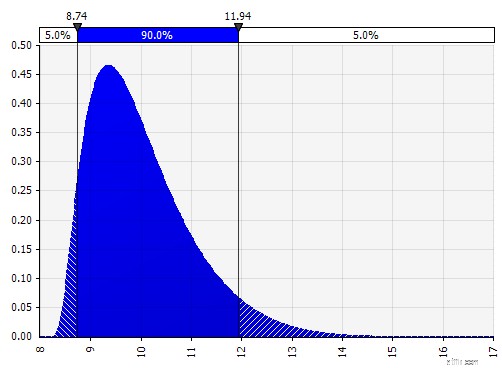
| Johnson Moments. Hvis du vælger dette, kan du definere skæve fordelinger og fordelinger med federe eller tyndere haler (teknisk tilføjelse af skævhed og kurtosis-parametre). Bag kulisserne bruger dette en algoritme til at vælge en af fire distributioner, som afspejler de fire valgte parametre, men det er usynligt for brugeren --- alt vi skal fokusere på er parametrene.
|  |
| Diskret. Hvor sandsynligheder er givet til to eller flere specifikke værdier. For at vende tilbage til eksemplet med et faset F&U-projekt i begyndelsen, modelleres sandsynligheden for succes på hvert trin som en binær diskret fordeling, med et resultat på 1, der repræsenterer succes og 0 fiasko. | 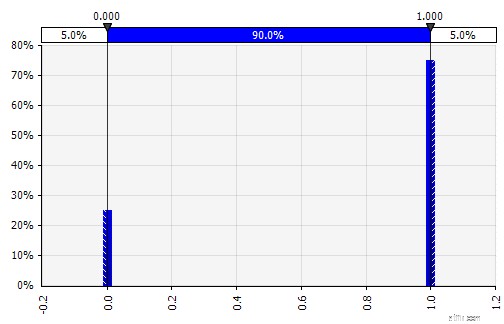 |
| Distributionstilpasning. Når du har en stor mængde historiske datapunkter, er fordelingstilpasningsfunktionen nyttig. Dette betyder for eksempel ikke tre eller fire års historisk salgsvækst, men tidsseriedata såsom råvarepriser, valutakurser eller andre markedspriser, hvor historien kan give nyttige oplysninger om fremtidige tendenser og graden af usikkerhed. | 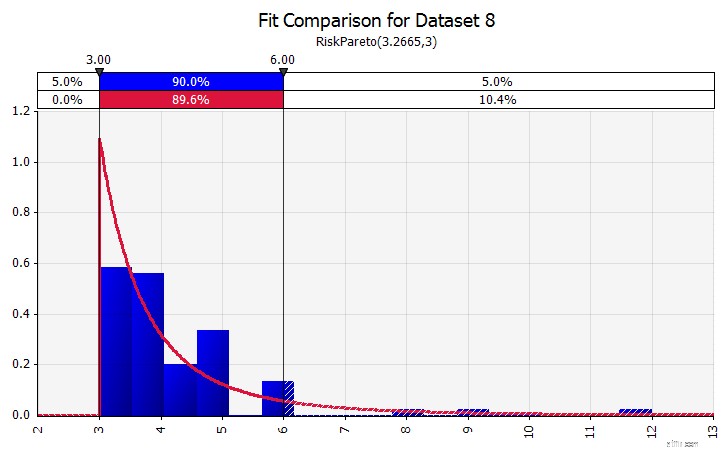 |
| Kombinering af flere forskellige distributioner til én. For at afbøde den potentielle påvirkning af individuelle skævheder er det ofte en god idé at inkorporere input fra forskellige kilder i en antagelse og/eller at gennemgå og diskutere resultaterne. Der er forskellige tilgange:
|  Vægt:20 % 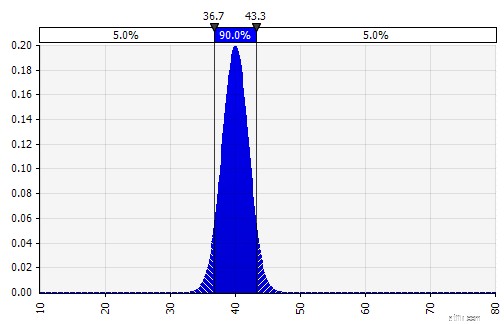 Vægt:20 % 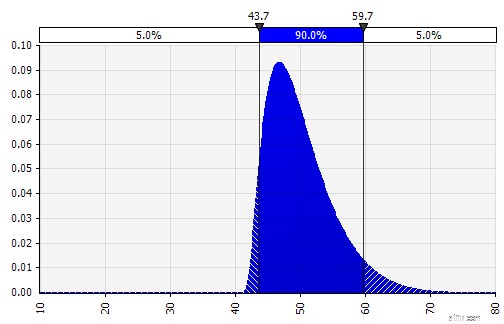 Vægt:60 % 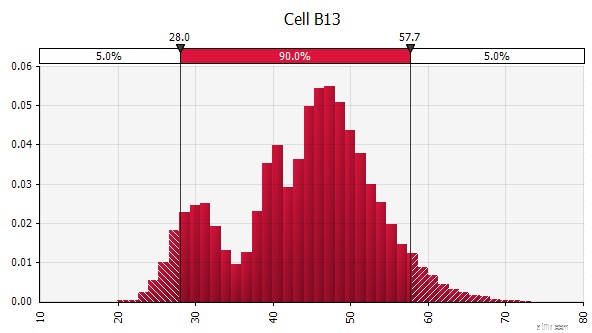 |
| Frihånd. For hurtigt at illustrere en distribution som en del af diskussioner, eller hvis du har brug for en distribution, når du udarbejder en model, der ikke er let at lave ud fra den eksisterende palet, er frihåndsfunktionaliteten nyttig. Som navnet antyder, giver dette dig mulighed for at tegne fordelingen ved hjælp af et simpelt maleværktøj. |  |
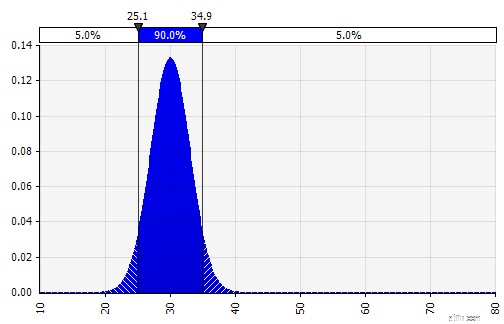
Nu ser vi en visualisering af fordelingen med et par parametre i venstre side. Symbolerne for middelværdi og standardafvigelse skal se velkendte ud. I tilfælde af en normalfordeling vil middelværdien være det, vi tidligere har indtastet som en enkelt værdi i cellen. Her er salgssandsynlighedsfordelingen for 2018 som et eksempel, hvor 10 % repræsenterer gennemsnittet. Mens din typiske model enten kun vil fokusere på tallet på 10 % eller have "tyr"- og "bjørne"-scenarier med måske henholdsvis 15 % og 5 % vækst, giver denne nu information om hele spektret af forventede potentielle resultater.
Sandsynlighedsfordeling af salgsvækst på et år
En fordel ved Monte Carlo-simuleringer er, at haleresultater med lav sandsynlighed kan udløse tænkning og diskussioner. Kun visning af op- og nedadgående scenarier kan introducere risikoen for, at beslutningstagere fortolker dem som de ydre grænser og afviser alle scenarier, der ligger udenfor. Dette kan resultere i mangelfuld beslutningstagning med eksponering for resultater, der ligger uden for organisationens eller individets tolerance over for risiko. Selv en 5 % eller 1 % sandsynlighed kan være uacceptabel, hvis det pågældende scenarie ville have katastrofale konsekvenser.
Med Monte Carlo-modellering skal du være opmærksom på, hvordan usikkerheds- og sandsynlighedsfordelinger stables oven på hinanden, f.eks. over tid. Lad os gennemgå et eksempel. Da salget i hvert år afhænger af væksten i de foregående, kan vi visualisere og se, at vores estimat for 2022-salget er mere usikkert end for 2018 (vist ved brug af standardafvigelser og 95 % konfidensintervaller i hvert år). For nemheds skyld specificerer nedenstående eksempel væksten for et år, 2018, og anvender derefter den samme vækstrate for hvert af de følgende år indtil 2022. En anden tilgang er at have fem uafhængige fordelinger, en for hvert år.
Illustrerer, hvordan usikkerhed stiger over tid (udvidelse af fordeling af resultater)
Vi estimerer nu en sandsynlighedsfordeling for EBIT-marginen i 2018 (fremhævet nedenfor) på samme måde som vi gjorde det for salgsvækst.
Her kan vi bruge korrelationsfunktionen til at simulere en situation, hvor der er en klar sammenhæng mellem relativ markedsandel og rentabilitet, hvilket afspejler stordriftsfordele. Scenarier med højere salgsvækst i forhold til markedet og tilsvarende højere relativ markedsandel kan modelleres til at have en positiv sammenhæng med højere EBIT-marginer. I brancher, hvor en virksomheds formue er stærkt korreleret med en anden ekstern faktor, såsom oliepriser eller valutakurser, kan det være fornuftigt at definere en fordeling for denne faktor og modellere en korrelation med salg og rentabilitet.
Modellering af sammenhæng mellem salgsvækst og marginer
Afhængigt af den tilgængelige tid, transaktionens størrelse og andre faktorer giver det ofte mening at opbygge en driftsmodel og indtaste de mest usikre variabler eksplicit. Disse omfatter:produktmængder og -priser, råvarepriser, valutakurser, vigtigste overhead-poster, månedlige aktive brugere og gennemsnitlig omsætning pr. enhed (ARPU). Det er også muligt at modellere ud over mængdevariabler såsom udviklingstid, time to market eller markedsadoptionshastighed.
Ved at bruge den skitserede tilgang kan vi nu fortsætte gennem balancen og pengestrømsopgørelsen, udfylde med antagelser og bruge sandsynlighedsfordelinger, hvor det giver mening.
En note om capex:dette kan modelleres enten i absolutte beløb eller som en procentdel af salget, potentielt i kombination med større trinvise investeringer; en produktionsfacilitet kan for eksempel have en klar kapacitetsgrænse og en stor udvidelsesinvestering eller en ny facilitet nødvendig, når salget overstiger tærsklen. Da hver af de f.eks. 1.000 eller 10.000 iterationer vil være en komplet genberegning af modellen, kan en simpel formel, der udløser investeringsomkostningerne, hvis/når en vis mængde nås, bruges.
Opbygning af en Monte Carlo-model har et ekstra trin sammenlignet med en standard finansiel model:De celler, hvor vi ønsker at evaluere resultaterne, skal specifikt udpeges som outputceller. Softwaren vil gemme resultaterne af hver iteration af simuleringen for disse celler, så vi kan evaluere efter simuleringen er færdig. Alle celler i hele modellen genberegnes med hver iteration, men resultaterne af iterationerne i andre celler, som ikke er udpeget som input- eller outputceller, går tabt og kan ikke analyseres, efter at simuleringen er færdig. Som du kan se på skærmbilledet nedenfor, udpeger vi MIRR-resultatcellen til at være en outputcelle.
Når du er færdig med at bygge modellen, er det tid til at køre simuleringen for første gang ved blot at trykke på "start simulering" og vente et par sekunder.
Output udtrykt som sandsynligheder. Mens vores model tidligere gav os en enkelt værdi for den modificerede IRR, kan vi nu tydeligt se, at der er en række potentielle udfald omkring den værdi, med forskellige sandsynligheder. Dette giver os mulighed for at omformulere spørgsmål, såsom "Vil vi ramme vores forhindringsrente med denne investering?" til "Hvor sandsynligt er det, at vi rammer eller overskrider vores forhindringsrate?" Du kan udforske, hvilke udfald der er mest sandsynlige ved at bruge for eksempel et konfidensinterval. Visualiseringen er nyttig, når du kommunikerer resultaterne til forskellige interessenter, og du kan overlejre output fra andre transaktioner for visuelt at sammenligne, hvor attraktiv og (u)sikker den nuværende er sammenlignet med andre (se nedenfor).
Ændret IRR med konfidensintervaller
Modificeret IRR med en Hurdle Rate
Ændret IRR med andre transaktioner overlejret
Forstå graden af usikkerhed i det endelige resultat. Hvis vi genererer et diagram over pengestrømsvariabilitet over tid, svarende til det, vi oprindeligt gjorde for salg, bliver det klart, at variabiliteten i frit cashflow bliver betydelig selv med relativt beskeden usikkerhed i salget og de andre input, vi modellerede som sandsynlighedsfordelinger , med resultater fra omkring €0,5 millioner til €5,0 millioner – en faktor på 10x – endda kun en standardafvigelse fra gennemsnittet. Dette er resultatet af at stable usikre antagelser oven på hinanden, en effekt, der både forværres "lodret" over årene og "vandret" ned gennem regnskabet. Visualiseringerne giver information om begge typer usikkerhed.
Variabilitet af frit cash flow sammenlignet med variation i salg
Sensitivitetsanalyse:Introduktion til tornadografen. Et andet vigtigt område er at forstå, hvilke input der har størst indflydelse på dit endelige resultat. Et klassisk eksempel er, hvordan betydningen af diskonteringsrente eller terminalværdiantagelser ofte vægtes for lidt i forhold til pengestrømsprognoser. En almindelig måde at håndtere dette på er ved at bruge matricer, hvor du sætter et nøgleinput på hver akse og derefter beregner resultatet i hver celle (se nedenfor). This is useful especially in situations where decisions hinge on one or a few key assumptions—in these “what you have to be believe” situations, decision-makers on (for example) an investment committee or a senior management team may have different views of those key assumptions, and a matrix such as the one above allows each one of them to find a result value corresponding to their view, and can decide, vote, or give advice based on that.
Example Sensitivity Analysis Matrix - Enterprise Value as a Function of the Cost of Capital and Year Five Exit Multiple
Enhancing with Monte Carlo simulations. When using Monte Carlo simulations, that approach can be complemented with another:the tornado diagram. This visualization lists the different uncertain inputs and assumptions on the vertical axis and then shows how large the impact of each is on the end result.
Tornado Diagram Showing Sensitivity to Key Inputs
This has several uses, one of which is that it allows those preparing the analysis to ensure that they are spending time and effort on understanding and validating the assumptions roughly corresponding to how important each is for the end result. It can also guide the creation of a sensitivity analysis matrix by highlighting which assumptions really are key.
Another potential use case is to allocate engineering hours, funds, or other scarce resources to validating and narrowing the probability distributions of the most important assumptions. An example of this in practice was a VC-backed cleantech startup where I used this method to support decision-making both to allocate resources and to validate the commercial viability of its technology and business model, making sure you solve the most important problems, and gather the most important information first. Update the model, move the mean values, and adjust the probability distributions, and continually reassess if you are focused on solving the right problems.
Probability is not a mere computation of odds on the dice or more complicated variants; it is the acceptance of the lack of certainty in our knowledge and the development of methods for dealing with our ignorance. – Nassim Nicholas Taleb
It is useful to distinguish between risk , defined as situations with future outcomes that are unknown but where we can calculate their probabilities (think roulette), and uncertainty , where we cannot estimate the probabilities of events with any degree of certainty.
In business and finance, most situations facing us in practice will lie somewhere in between those two. The closer we are to the risk end of that spectrum, the more confident we can be that when using probability distributions to model possible future outcomes, as we do in Monte Carlo simulations, those will accurately capture the situation facing us.
The closer we get to the uncertainty end of the spectrum, the more challenging or even dangerous it can be to use Monte Carlo simulations (or any quantitative approach). The concept of “fat tails,” where a probability distribution may be useful but the one used has the wrong parameters, has received lots of attention in finance, and there are situations where even the near-term future is so uncertain that any attempt to capture it in a probability distribution at all will be more misleading than helpful.
In addition to keeping the above in mind, is also important to 1) be mindful of the shortcomings of your models, 2) be vigilant against overconfidence, which can be amplified by more sophisticated tools, and 3) bear in mind the risk of significant events that may lie outside what has been seen before or the consensus view.
There are two concepts here and it is important to separate them:one is the recognition of uncertainty and the mindset of thinking in probabilities, and the other is one practical tool to support that thinking and have constructive conversations about it:Monte Carlo simulations in spreadsheets.
I don’t use Monte Carlo simulations in all models I build or work on today, or even a majority. But the work I have done with it influences how I think about forecasting and modeling. Just doing this type of exercise a few times, or even once, can influence how you view and make decisions. As with any model we use, this method remains a gross simplification of a complex world, and forecasters in economics, business, and finance have a disappointing track record when evaluated objectively.
Our models are far from perfect but, over years and decades, and millions or billions of dollars/euros invested or otherwise allocated, even a small improvement in your decision-making mindset and processes can add significant value.
I spend 98% of my time on 2% probabilities – Lloyd Blankfein
Sådan udfører man pligterne som bobestyrer for et dødsbo
Hvorfor jeg hader Monte Carlo-analyse og andre finansielle fremskrivninger
Sæt ikke din pension på Monte Carlo-modeller
Hvad er kvalitativ analyse af aktier? Og hvordan udføres det?
Forklaret:Hvordan er PESTLE-analyse (med eksempel)? Hvordan udføres det?